一年前,我在 git 上发布了一个用 Swift 实现的栈,一共有两个版本。因为 Swift 自身并没有实现这个东西——尽管官方的教程中泛型的部分就是用这个栈举的例子。
也许是人家觉得这个太简单了吧
总之,这次我又来玩这个东西了,因为 HMM 的 Viterbi 算法需要做修剪,不然路径太多无谓地增加计算量——毕竟,我们都关心第一名,谁会去注意第二名呢?
所以,这个栈也是基于原生 Array 的。几本思路与普通的栈相同,不过这次我们使用结构体来做。
在 Swift 后台,实际上对于结构体和类区分的不是特别严谨,只有真正需要区分的时候才会有不同的行为。这里 Swift 后台都做了优化。
首先我们还是先摆一个普通的栈:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
struct PriorityStack<Element> { fileprivate var items:[Element] = [] let maxLength:Int init(Length length:Int) {//长度固定,这样栈才能把小的元素自动丢弃 maxLength = length } mutating func push(_ newElement:Element) { } mutating func pop()->Element? { guard count > 0 else {return nil} return items.removeFirst() } func empty() -> Bool { return items.isEmpty } func peek() ->Element? { return items.last } var count:Int { return items.count } } |
这里没有什么区别,对吧?首先,我们要让元素可以比较,毕竟,你想要给它们排序:
|
1 |
struct PriorityStack<Element:Comparable> { |
所以我们让泛型限定为遵循 Comparable 的类型。
接下来就是处理入栈了,这里我们借鉴了快速排序和插入排序算法(实际上是我自己设计的排序算法,我是后来才知道的原来有专门的排序算法,而且似乎是各种开发面试的必考内容……?♂️)
总之,我重新发明了一遍轮子,也不好意思说我自己设计了算法,只好说借鉴了……
大致的流程
1、就是我们先判断栈是不是满了,如果满了且新元素比最小的还小,那么就丢弃:
|
1 2 3 |
if maxLength == count && newElement < items.last! { return } |
2、如果栈还是空的,那么直接添加:
|
1 |
if items.isEmpty {items.append(newElement);return} |
3、这下有意思了,我们利用折半思想(其实就是快排的分块),从数组现有数据数量的中间开始比较如果比中间的值大那么就往上走,如果小就往下走,直到找到那个合适自己的位置然后插入:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
var middleIndex = Int(count/2) if newElement > items[middleIndex] { while middleIndex >= 0 { if newElement > items[middleIndex] { if middleIndex == 0 {items.insert(newElement, at: 0)} middleIndex -= 1 continue } items.insert(newElement, at: middleIndex + 1) break } } else { while middleIndex < count { if newElement < items[middleIndex] { if middleIndex == count - 1 {items.append(newElement)} middleIndex += 1 continue } items.insert(newElement, at: middleIndex) break } } |
4、最后,如果栈的长度(这里也许应该说是高度),总之,如果长度等于我们设定的值,这时候又插入了一个有效的(就是比栈里边最小值还大的)值,那么栈的长度就溢出了1,那么就:
|
1 |
if count > maxLength {items.removeLast()} |
这样,栈内部的 items 就是自动排好序的啦!
然后,以防你已经读懂,我再上个流程图:
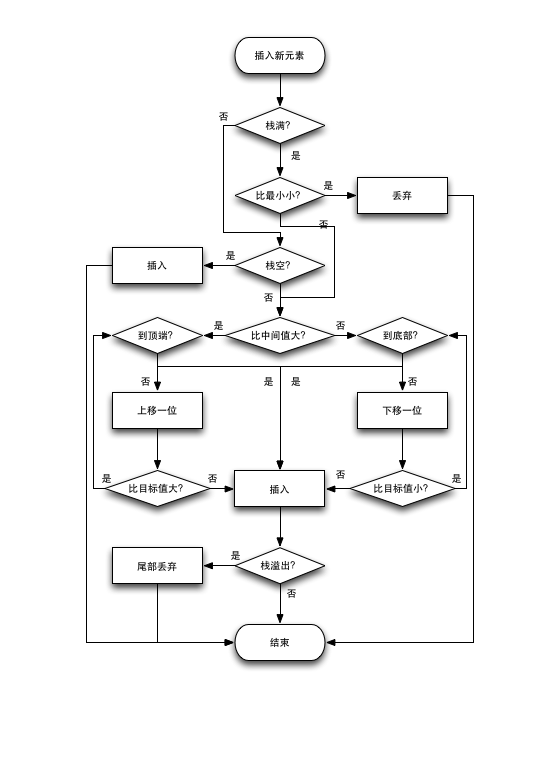
排序算法流程
当然,使用起来可能不是很方便,毕竟有时候我们要获取这个栈的list,所以,让它遵循 Sequence 就很有必要。
Sequence
这是 Swift 里的一个协议,所有遵循它的类型就可以被 for-in 遍历了,当然,对应的还有比如 map 之类的方法也就自动有了,简单来讲就是你可以把它当作一个Array 来对待了!
那么,怎么办呢?如果你点开 Sequence,你会发现声明的方法太多了——实际上不需要全部去实现,因为 Swift 已经帮你实现好了,你需要做的仅仅是实现这两个:
|
1 2 |
typealias Iterator func makeIterator() -> PriorityStack.Iterator |
就是这么简单!
不过,其实也很难,因为这里可能有点绕,那就是由于我们并不是要遍历自身,而是要遍历栈内部的 Array,所以实现起来很简单但思路和直接实现 Sequence 不一样。
首先,你不需要去实现一个遵循 IteratorProtocol 的遍历器,因为我们的基础结构就是数组,它自己就有不是吗?
其次,你也不需要实现 makeIterator() ,理由同上。
所以,我们点开数组的 makeIterator() ,可以看到它返回了一个 IndexingIterator<Array<Element>> ,再点进去看到这是一个结构体——总之,不用管它,我们只要也返回这个类型就好了,然后 makeIterator() 返回基础数组自身的 makeIterator() 即可,所以,实际上代码是这样的:
|
1 2 3 4 5 6 |
extension PriorityStack:Sequence { typealias Iterator = IndexingIterator<Array<Element>> func makeIterator() -> PriorityStack.Iterator { return items.makeIterator() } } |
这下,当你对 PriorityStack 做任何遍历操作,都相当于是对其内部的数组做了——不需要额外地写一个getter来取出数组再操作。
那么,举个栗子:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
var pStack:PriorityStack<Int> = PriorityStack(Length: 5) pStack.push(1) pStack.push(5) pStack.push(2) pStack.push(8) pStack.push(100) pStack.push(999999) pStack.push(0) print(pStack.maxLength) print("---") for item in pStack { print(item) } let list:[Int] = pStack.map{return $0} print(list) |
然后呢?
好了,这篇总结就到这里,我已经把我的Stack-in-Swift更新了,里边加入了这个自动排序栈,你可以去下载然后看一看它的完整代码。
另外,如果你想了解快排,那么可以看这里:http://bubkoo.com/2014/01/12/sort-algorithm/quick-sort/
还有插入排序:https://zh.wikipedia.org/zh-hans/插入排序
本文由 落格博客 原创撰写:落格博客 » 一个自动排序的 Swift 栈
转载请保留出处和原文链接:https://www.logcg.com/archives/2530.html